探营腾讯混元大模型

目前,中国大模型领域的竞争,已经进入一个群雄逐鹿的乱战时代。
截止4月上旬,国内已有多家头部企业发布/或预发布了自己的大模型,其中包括了:
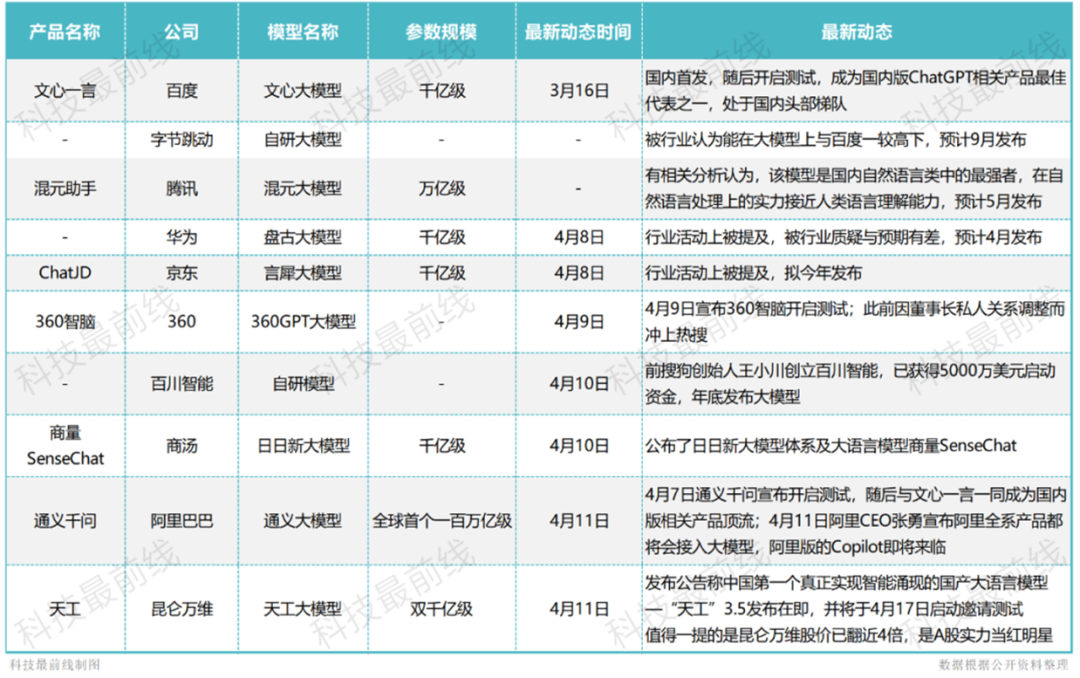
1、 百度(NASDAQ:BIDU)的文心一言
2、华为的大模型盘古
3、阿里(NYSE:BABA)的大模型通义千问
4、商汤科技的日日新大模型
5、腾讯(HK:00700)的混元大模型
一时间,“寻找或成为中国的OpenAI”,成为了国内各企业最首要的问题。
虽然科技创新讲究的就是一个“快”字,但“快”也不是一味的。
如何在保证速度的同时,解决好资金、算力、数据、人才,以及更多未知的工程化方法,都是一个颇为考验“内功”的环节。
目前,互联网行业中的一些企业,已经在大模型领域展现出了自己的实力,比如阿里这类领军企业,但同时,还有像腾讯这样实力不容小觑的企业尚未发力。
腾讯作为互联网行业的领军企业之一,拥有强大的技术实力、丰富的数据积累以及AI基础设置,让其在AIGC领域的布局备受关注。
01 万亿大模型
自OpenAI发布Chatgpt以来,大模型领域一个明显的趋势,就是随着算力的发展,模型容量持续提升,模型通用性和泛化能力也更强。
然而,此前国内基于万亿大模型的应用探索极少,在高速网络、训练/推理框架、模型算法和落地应用等方面,也没有全面深入的公开性研究。
在这种情况下,作为头部企业之一的腾讯,自然动了欲作开拓者的野心。
然而,若要问鼎“万亿大模型”这枚王冠,强大的算力则是必不可少的。于是,腾讯设计的一套“先蒸馏后加速”的大模型压缩方案——太极-HCF ToolKit,就应运而生了。

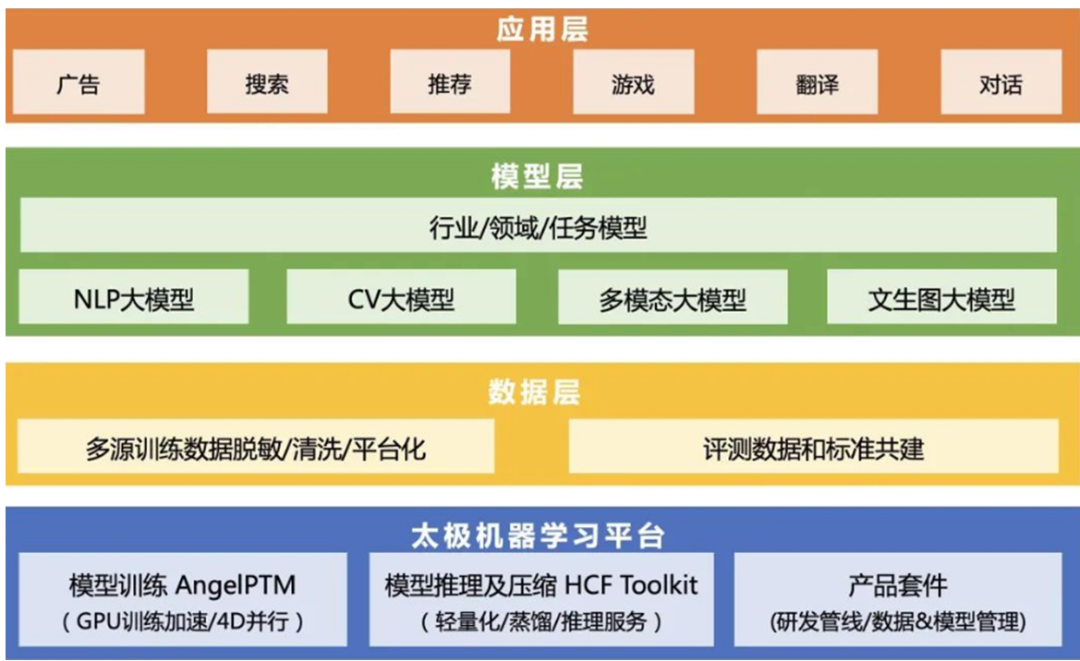
太极平台,包含了从模型蒸馏、压缩量化到模型加速的完整能力,为AI工程师打造从数据预处理、模型训练、模型评估到模型服务的全流程高效开发工具。
由于太极框架封装了很多功能和验证,因此只要配置正确,就不需要再进行额外的测试。这大大加快了开放的进度。
以太极平台的基础,配合强大的底层算力与低成本的高速网络基础设施,腾讯打造了首个可在工业界海量业务场景直接落地,并投入应用的万亿NLP大模型——HunYuan-NLP 1T(以下简称混元)。
混元最快仅用256卡在一天内即可完成万亿参数大模型的训练,整体训练成本仅为直接冷启动训练万亿模型的1/8。
而腾讯之所以在训练成本上如此大费周章,则与其自身的战略布局有着密切的关系。
纵观混元在腾讯应用层、模型层的布局,我们可以发现,这样的布局策略,很有可能是想以统一的平台,实现技术复用和业务降本,支持更多的场景和应用。
而这样的技术复用和多场景支持,则与腾讯在互联网领域独特的生态位有着密切关系。
腾讯目前已有的互联网江山,涵盖了社交、游戏、广告、内容创作等多个领域,如何用最低的成本,为原先已有的众多产品和业务进行赋能和升级,就成了腾讯在AI时代首先要考虑的问题。
目前,腾讯已经打造了以混元 AI 大模型为技术底座的广告多媒体 AI 技术矩阵;以及应用于创作的智能创作助手;和通用游戏竞技 的AI“绝艺”+“绝悟”。
可以说,这种通过降低模型训练成本,从而迅速让AIGC 技术为多个领域赋能的做法,与互联网行业发展初期,很多企业通过“烧钱”的方式,以迅速扩大市场份额的策略,着实有一种“异曲同工之妙”。
02 AIGC时代的新“微信”
“混元”对腾讯 AI 应用生态的拓展,绝不仅仅是一次对原有业务的“纵向升级”。
从某种程度上说,这样的生态的拓展,体现了腾讯在人工智能时代,对社会各领域、各产业层面的新一轮商业渗透的展开。
而这种多元化布局的思路,可以说是对其在移动互联网时代“攻城略地”的一次复刻。
在移动互联网时代,腾讯的野心就已经四溢到了游戏、社交、金融、广告等多个领域。这种多元化的业务布局,使得腾讯的触手深入到了网络生活的各个方面,并最终通过微信这个终端,一步步整合了人们对于衣食住行的大部分需求,以至于到了人们难以对其脱离的地步。
在当下的社会中,人们几乎无法想象没有微信的生活会是怎样的。
在进行多元化布局的同时,通过“烧钱”的方式不断投资并购,也是腾讯壮大自身的另一大手段。
如京东、美团、滴滴等,这些企业都是行业内的领先者,与腾讯的业务有很强的互补性,能够为腾讯带来更多的商业机会和收益来源,从而进一步扩大了腾讯自身的业务版图。
然而,随着互联网红利消失, 市场已经进入相对平稳的发展阶段,各大巨头们也开启了从增量到存量的战争。
在这样的背景下,传统的“花钱买量”已经难以再带来新的用户增长,既然原有产品的“纵向增量”已经走到尽头,那么通过跨领域融合的“横向增量”方式,继续维持或扩大自身庞大的业务版图,就成了腾讯若要在AIGC时代,一种最可行的策略。
凭借已有的庞大的用户数据,加上大模型带来的开放平台、生态合作,将自身的业务逐渐与农业、医疗、工业、教育等领域融合,可以最终编织成一张深深嵌入社会各个领域的智能化网络。
正如移动互联网时代,微信通过二维码、朋友圈、小程序等功能的推出,不断扩宽了自身的应用场景,并实现了用户数的一次次飞跃。
在人工智能时代,通过混元大模型带来的通用+专用领域的融合功能,意味着腾讯能够将各个领域的数据和信息进行整合和分析,混元大模型可以提供更加个性化、智能和高效的服务,从而进一步增强用户的忠诚度和粘性。
而当这些来自多个领域的信息、数据,最终被大模型整合进某一终端时,一个涵盖了人们各个不同领域需求的“AIGC版微信”,或许也就此诞生了。
在某种程度上,它可能会比现在的微信更“必要”、更“难以离身”,得益于大语言模型知识抓取、逻辑分析能力,一些涉及事项多、专业性强,并且与民众需求紧密相连的需求(如医疗、法律等领域),最后甚至仅仅能通过人们一句简单的“命令”,得到实现。
如此一来,混元大语言模型,从理论上可以打破腾讯的原有的产品版图边界,让AI连接起各个产品与用户之间的需求。
03 算力的边界
若要支撑起这样横跨各领域、多业务的大模型生态,一道绕不过去的坎,就是算力的限制。
尽管大模型概念持续火热,但入局者大多面临着算力之困。
市场上流传的调研纪要显示,要训练像ChatGPT这样的生成式AI,至少需要1万张英伟达A100加速卡的支持。目前,国内只有6家公司具备这样的硬件实力。

然而,这样的“算力边界”,并没能阻止腾讯在AIGC时代扩充自身版图的野心。
4月14日,腾讯云正式发布了面向大模型训练的新一代高性能计算集群HCCPNV5。
该集群采用最新一代腾讯云星星海自研服务器,并搭载了英伟达 H800 Tensor Core GPU(国内首发),提供业界目前最高的3.2Tbps超高互联带宽,算力性能比前代提升了3倍。

H800 Tensor Core GPU
一般来说,一个集群的性能,主要取决于三个要素:单机算力、网络架构、存储性能。
在单卡单机的算力上,新一代集群单GPU卡支持输出最高495 TFlops(TF32)、989 TFlops (FP16/BF16)、1979 TFlops(FP8)的算力,单卡性能爆表。
而得益于腾讯云星星海服务器采用6U超高密度设计,每节点支持8块H800,上架密度与同行相比提升了30%。利用并行计算理念,通过CPU和GPU节点的一体化设计,将单点算力性能提升至最强。

然而,仅仅有了先进的芯片,并不等于拥有先进算力。
原因在于高性能计算存在“木桶效应”,一旦计算、存储、网络任一环节出现瓶颈,就会导致运算速度严重下降。
因此,先进算力的背后是先进芯片、先进网络、先进存储等一系列的支撑,缺一不可。
此次腾讯自研的星脉网络,为新一代集群带来3.2T的超高通信带宽。在「星脉网络」的加持下,单集群规模支持4K GPU(最大支持10万+ GPU)、超EFLOPS(FP16)算力。
搭载同样的GPU卡,3.2T星脉网络相较前代网络,能让集群整体算力提升20%,使得超大算力集群仍然能保持优质的通信开销比和吞吐性能。并提供单集群高达十万卡级别的组网规模。

最后的存储问题,在大模型训练场景下,存储也经受着前所未有的考验。
几千台计算节点会同时读取一批数据集,需要尽可能地缩短数据集的加载时长。
而新一代HCC集群,引入了腾讯云最新自研存储架构,支持不同场景下对存储的需求。

例如其中的COS+GooseFS方案,就提供基于对象存储的多层缓存加速,大幅提升了端到端的数据读取性能;
而CFS Turbo多级文件存储方案,则充分满足了大模型场景下,大数据量、高带宽、低延时的存储要求。
如此一来,算力、网络、存储,三个关键的节点,都被腾讯一一攻克了。
随着新一代HCC高性能计算集群的发布,国内大模型训练面临的算力困局有望得到纾缓,而国内的人工智能生态,也有可能从此走向百花齐放的局面。
这是因为,虽然对于中国企业来说,虽然ChatGPT这样大模型,工作量和成本并不是不可接受,但只有在算力、算法、数据等不同环节,让众多公司构成了一个庞大的人工智能生态,量变引起质变,中国自己的世界级大模型,才会有“涌现”的基础。
说到底,ChatGPT不是OpenAI一家公司的成功,而是一种人工智能生态的成功。
随着混元大模型所带来的低成本训练红利,国内大模型多元化格局也有望就此形成,而由此构建出的人工智能生态,也将有望让ChatGPT这类AI发生在中国、根植在中国。